DynaHeap: Dynamic DRAM Partitioning Between Managed Heap and Page Cache
Abstract
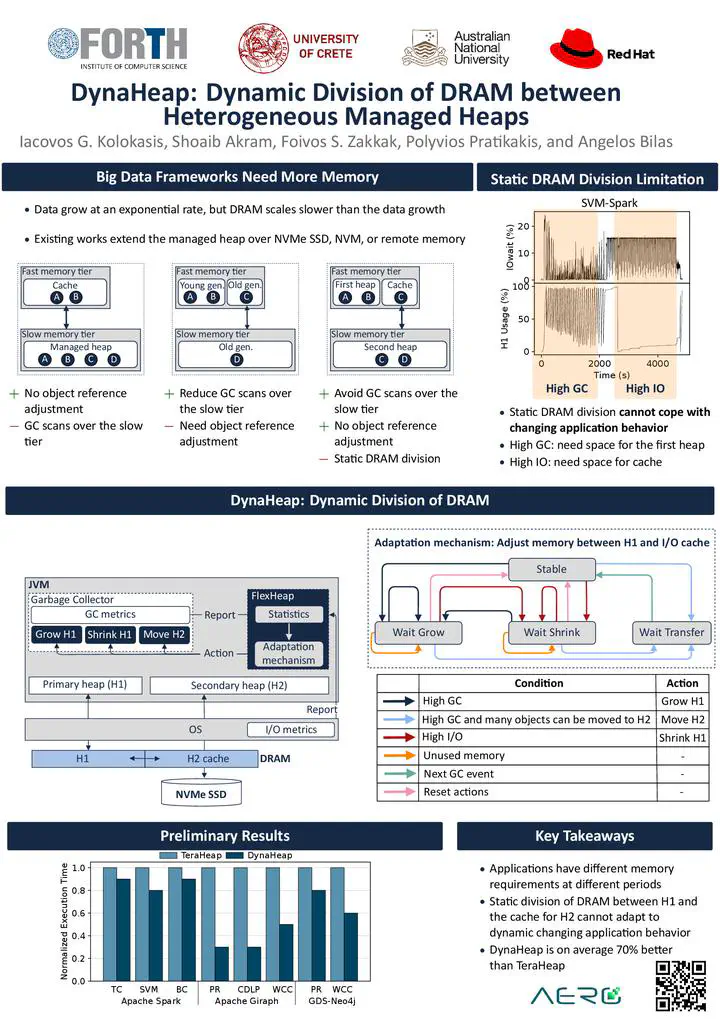
Popular big data frameworks running on top of managed runtimes must process datasets that typically outgrow DRAM capacity. Existing approaches extend the managed heap over slow but high-capacity media other than DRAM. The state-of-the-art avoids costly garbage collection (GC) scans over the slow tier using two managed heaps, one in each tier. They use a DRAM (I/O) cache to offer fast access to objects in the slow tier. However, existing systems partition DRAM between the DRAM heap and I/O cache statically, requiring tedious hand-tuning, which is impractical in real-life deployments and cannot adapt to dynamically changing application behavior.
This talk presents DynaHeap to address the problem of dynamically dividing a fixed DRAM budget between the DRAM heap and I/O cache for the slow tier. DynaHeap relies on three concepts: (1) it considers GC and I/O costs for periodically (re)partitioning DRAM, (2) it eliminates hand-tuned configurations using an adaptation mechanism that maintains a suitable division of DRAM without application knowledge, and (3) it flexibly adapts to applications behavior.
We evaluate DynaHeap compared to TeraHeap, a state-of-the-art dual-heap managed runtime system, using three real-world analytics frameworks: Spark, Giraph, and GDS-Neo4j. DynaHeap dynamically adjusts to applications memory needs for DRAM heap and I/O cache, improving performance compared to TeraHeap. In DRAM-constrained datacenter environments in particular, DynaHeap outperforms DynaHeap by up to 3.9x.
Iacovos Kolokasis
Graduate Research Assistant
My research interests include distributed robotics, mobile computing and programmable matter.